
import requests
from bs4 import BeautifulSoup
import time
chushiurl="http://www.**.cc/seojs/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"Cookie": "PHPSESSID=gpkit3qd1vftnhhkorf0a31d64; Hm_lvt_e3e00d6e883c992081f3141e552754a0=1597818420; Hm_lpvt_e3e00d6e883c992081f3141e552754a0=1597830064"
}
num = 0
def get_mulu():
res = requests.get(chushiurl, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
muluurls = soup.find(class_="fesleftnav").find_all('a')
for mululink in muluurls:
link = mululink.get("href")
fan_ye(link)
def fan_ye(link):
res = requests.get(link, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
fanyes = soup.find(class_="pageRemark")
fan=fanyes.find_all("b")
yema=int(fan[0].text)
print(yema)
if yema>10:
for num in range(yema):
url=link+"/page/"+str(num+1)
get_xiang(url)
else:
get_xiang(link)
def get_xiang(link):
res=requests.get(link,headers=headers)
soup=BeautifulSoup(res.text,'lxml')
xiangurls=soup.find_all(class_="feslist_right1_l")
for url in xiangurls:
lua=url.find("a")
lul=lua.get("href")
get_neirong(lul)
def get_neirong(lul):
res = requests.get(lul, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
neirong = soup.find(class_="wangEditor-container")
biaoti = soup.find('h1')
try:
biaoti=biaoti.text
biaoti=biaoti.strip("\n")
biaoti=biaoti.strip()
neirong=neirong.text
xie_ru(biaoti,neirong)
except:
print(lul)
def xie_ru(biaoti,neirong):
with open("bb/"+biaoti+".txt","w+",encoding="utf-8") as f:
f.write(neirong)
f.close()
'''
conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", password="", database="saiweianquan2",
charset="utf8")
cursor_test = conn.cursor()
str1='"'+biaoti+'"'
str2='"'+neirong+'"'
global num
sql3 = 'insert into user2 (ID,biaoti,CONTENT) values (%s,%s,%s);'
sql3 = sql3 % (num,str1, str2)
try:
cursor_test.execute(sql3)
conn.commit()
except:
print("插入失败")
conn.close()
num+=1'''
if __name__ == '__main__':
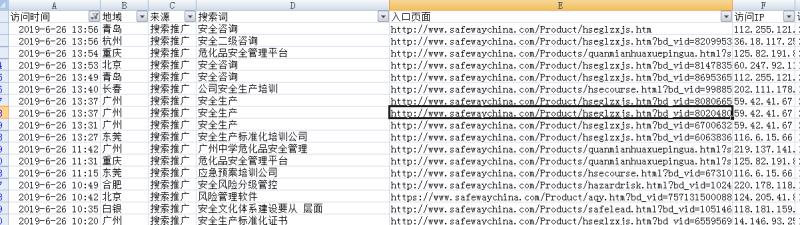
get_mulu()刚学习python爬虫知识的时候,就写了这么一个只要提供网站的新闻分类,就可以抓取其所有子分类及内容的程序,现在给大家分享一下,代码如上,爬取的效果如下图:

下一篇: 爱番番创建的潜客定投如何绑定到推广计划中
上一篇:手机网站如何优化?









评论