python爬虫
-

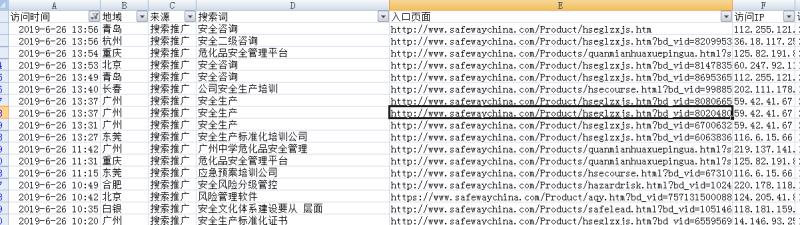
用pyhon写的一个一键抓取网站所有页面,并排除非本网链接的脚本
最近一直在思考如何能做一个想百度一样的爬虫,能够自行的爬取网站里所有页面,并且排除掉非该网站下的链接。于是,就写了以下的这么个程序。由于本人对于线程还不是了解,刚开始写的初稿并没有加上线程,导致遇到数据多一些的网站,脚本运行时间就很长。这个其实是非常烦恼的,因...
-

python关键词排名查询代码升级版
import requestsfrom fake_useragent import UserAgentfrom bs4 import BeautifulSoupua&nb...
-

python随机启动浏览器,并实现关键词搜索与查找功能代码
import timeimport randomfrom selenium import webdrivera=random.randint(1,3)if a==1: ...
-

如何使用python自动搜索,并点击搜索结果
这里是简单版本的自动搜索,并点击,我们只需要输入自己想要搜索的关键词,然后就会自动打开百度搜索,并且将结果一个一个点开,并关闭,这里因为是展示,只设置了搜索第一页,下面是完整代码:import timefrom selenium&nbs...
-

如何用python抓取爱企查企业信息
前段时间,经理让我去找一些企业的信息,我平常习惯于使用爱企查。所以,便想着写一个程序来实现这个,所以有以下的代码:import jsonimport requestsimport refrom lxml&nb...
-
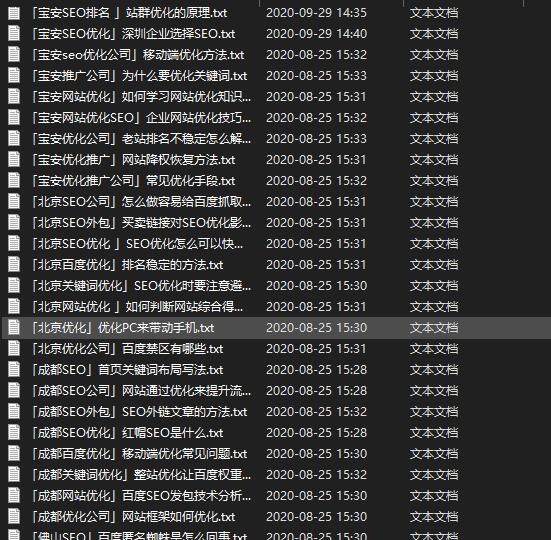
如何python抓取网站新闻目录下面的所有子分类及内容?
import requestsfrom bs4 import BeautifulSoupimport timechushiurl="http://www.**.cc/seojs/&...