
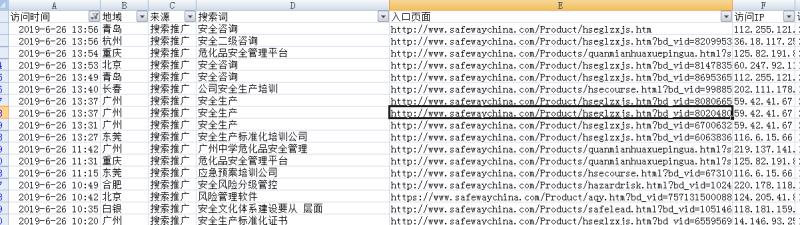
前几天不是用python写了一个一建抓取网站所有链接的小脚步吗,我在里面提了下脚步有点问题,但是不会影响大局观,所以就没有提出来。然而多次运行该脚步后发现了一个对大局观有很大影响的BUG,lia['href']遇到a标签中没有href时,就会像个哈比一样不知道怎么办,这是我在抓取自己博客的时候发现的一个问题,所以脚步写好了,要看其兼容性是否好,还得多找些案例来运行下才行。
好了,遇到问题就要解决问题。获取a标签中的href我在之前就写过相关脚步,但是具体怎么写的,因为年纪大了忘记了,这下遇到了问题,不得不重新去一个一个的翻找之前写的脚步,终于找到了,之前使用的是lia.get('href'),试一试的态度用一下,发现OK啦。效果看图吧。

有href运行的结果

没有href运行的结果
所以,这里提醒大家一下,以后如果想获取网站里的所有a标签,还是用get方法比较好。
下一篇: 百度网址移动搜索展现形式改变,品牌词代替
上一篇:搜索引擎如何识别网站的买卖链接




评论