
网站关键词库是什么意思,怎么增加网站关键词库?
一年的时间过得好快啊,今天已经是2022-07-13了,今年大环境不怎么好,很多人在这半年里,收入都非常少,小编同样如此,所以只能不断学习,提升自己,今天又掌握了一个新的知识,是关于网站关键词库是什么意思,怎么增加网站关键词库?的,下面来给大家分享一下:
搜索引擎是互联网发展的一个标志性产物,它的出现给予网民很大程度上的帮助,比如知识的获取等,搜索引擎的工作原理也是相当复杂的,身为SEO优化人员我们需要了解搜索引擎前世今生,这样才能使我们的优化工作有迹可循,而不是盲目的去做未知的事情。
搜索引擎有哪些类别?

随着互联网的快速发展,搜索引擎品类逐渐增多,由原来的百度搜索引擎发展到如今的头条搜索、360搜索、搜狗搜索、必应搜索、神马搜索等等。其中百度搜索引擎的市场占有率是最高的,达到70%以上。
一方面是因为百度搜索引擎的出生比较早,吸引到了一部分用户群体;另外一方面则是由于不断的更新升级功能比较完善,能够很大程度上解决用户需求,因此用户就选择它。
搜索引擎的工作原理:
搜索引擎的工作原理一:网页抓取
搜索引擎有一个非常棒的小助手,叫做搜索引擎蜘蛛,可以将搜索引擎本身想象成一个母体,蜘蛛就是它的孩子,蜘蛛的工作就是爬行到各个网站将新鲜的内容标记储存,搜索引擎使用多个蜘蛛分布爬行以提高爬行速度。
搜索引擎的服务器遍布世界各地,每一台服务器都会派出多只蜘蛛同时去抓取网页。如何做到一个页面只访问一次,从而提高搜索引擎的工作效率。
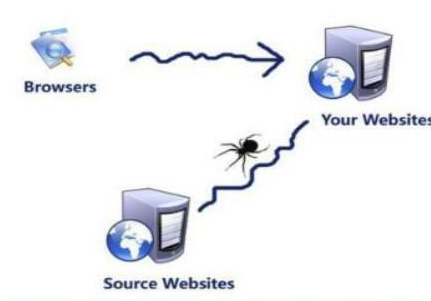
在抓取网页时,搜索引擎会建立两张不同的表,一张表记录已经访问过的网站,一张表记录没有访问过的网站。当蜘蛛抓取某个外部链接页面URL的时候,需把该网站的URL下载回来分析,当蜘蛛全部分析完这个URL后,将这个UR
如www.liaojinhua.com
L存入相应的表中,这时当另外的蜘蛛从其他的网站或页面又发现了这个URL时,它会对比看看已访问列表有没有,如果有,蜘蛛会自动丢弃该URL,不再访问。
搜索引擎的工作原理二:预处理,建立索引
由于互联网上的信息过于庞大,搜索引擎就需要对这些抓取的内容进行预处理,意思就是说通过搜索引擎工作方法将这些符合标准的页面储存起来,经过搜索引擎分析处理后,web网页已经不再是原始的网页页面,而是浓缩成能反映页面主题内容的、以词为单位的文档。
数据索引中结构最复杂的是建立索引库,索引又分为文档索引和关键词索引。每个网页唯一的docID号是有文档索引分配的,每个wordID出现的次数、位置、大小格式都可以根据docID号在网页中检索出来。最终形成wordID的数据列表。
搜索引擎的工作原理三:搜索词处理
用户在搜索引擎界面输入关键词,单击“搜索”按钮后,搜索引擎程序即对搜索词进行处理,如中文特有的分词处理,去除停止词,判断是否需要启动整合搜索,判断是否有拼写错误或错别字等情况。搜索词的处理必须十分快速。
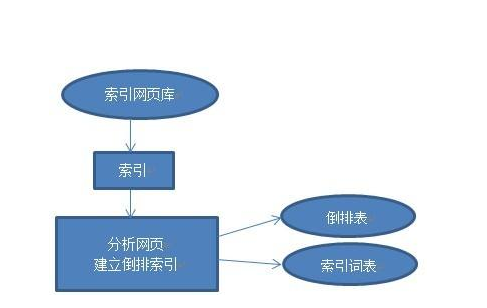
搜索引擎的工作原理四:排序
对搜索词处理后,搜索引擎程序便开始工作,从索引数据库中找出所有包含搜索词的网页,并且根据排名算法计算出哪些网页应该排在前面,然后按照一定格式返回到“搜索”页面。
再好的搜索引擎也无法与人相比,这就是为什么网站要进行搜索引擎优化(SEO)。没有SEO的帮助,搜索引擎常常并不能正确的返回最相关、最权威、最有用的信息。
主流搜索引擎蜘蛛介绍:
1、百度蜘蛛:可以根据服务器的负载能力调节访问密度,大大降低服务器的服务压力。根据以往的经验百度蜘蛛通常会过度重复地抓取同样的页面,导致其他页面无法被抓取到而不能被收录。这种情况可以采取robots协议的方法来调节。
2、谷歌蜘蛛:谷歌蜘蛛属于比较活跃的网站扫描工具,其间隔28天左右就派出“蜘蛛”检索有更新或者有修改的网页。与百度蜘蛛最大的不同点是谷歌蜘蛛的爬取深度要比百度蜘蛛多一些。

3、微软必应蜘蛛:必应与雅虎有着深度的合作关系,所以基本运行模式和雅虎蜘蛛差不多。
4、搜狗蜘蛛:搜狗蜘蛛的爬取速度比较快,抓取的数量比起速度来说稍微少点。最大的特点是不抓取 robots. txt文件。
以上内容就是搜索引擎的工作原理的相关介绍,实际上搜索引擎的工作是一个相当复杂的过程,而它的原理也如人类大脑一样,对海量数据进行有序处理,由此不得不佩服搜索引擎工程师,如果你对搜索引擎的工作还有其他的问题欢迎与龙斗SEO博主交流互动。
总结:要想做好seo,最好的办法就是不断实践,不断探索。关于网站关键词库是什么意思,怎么增加网站关键词库?的探索,今天就到此为止,以后小编还会将更多探索到的SEO知识分享出来给大家,希望能够帮助更多的SEO初学者。





评论