python
-

python中同为替换函数,replace与sub相比有何不同
在python中replace与sub两个函数都有替换某个字符或者字符串的功能,那么在实战中他们由什么区别呢?要想知道他们的不同点,只需要用代码打印一下就知道了,首先我们来看看以下代码:
... -

python+selenium+Chrome options参数设置详解
Chrome Options常用的行为一般有以下几种:禁止图片和视频的加载:提升网页加载速度。添加代理:用于翻墙访问某些页面,或者应对IP访问频率限制的反爬技术。使用移动头:访问移动端的站点,一般这种站点的反爬技术比较薄弱。添加扩展:像正常使用浏览器一样的功能。设置编码:应对中文站,防止乱码。阻止JavaScript执行...Chrome Options是一个配置chrome启动时属性的类,通过这个参数我们可以为Chrome添加如下参数:设置 chrome 二进制文件位置 (binary_loc ...
-
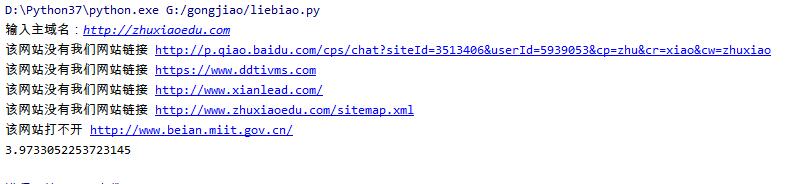
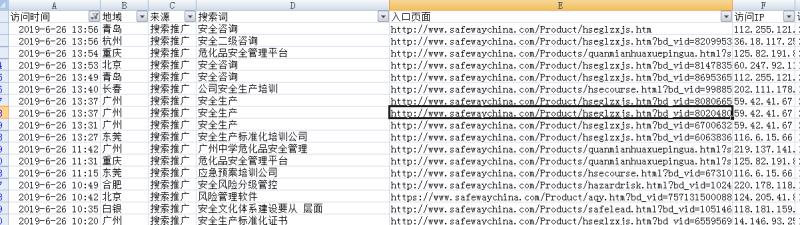
python实现网站友情链接查询与网站死链接查询的两个脚步
在前几天写的一建抓取网站所有链接的脚步往后衍生了以下的两个脚步,一个是查询网站友情链接,另一个是查询网站的死链。我这里只是初步实现了功能,还有很多地方需要优化,比如说查询友情链接脚步会存在带www与不带www不能共存识别的问题,查询网站死链的脚步运行好慢的问题,这个问题是我目前解决不了的,我的能力还有限。很多人说,爬虫学的好,“劳烦”吃的 饱。所以,在爬虫教程中,都会劝说大家善良,但是我现在能力有限,可以随便放开造,如果有喜欢一起学习的朋友,可以加我微信,相互讨论,共同学习。下面分享这两个脚步源 ...
-
![获取网页所有a标签中的超链接,使用['href']好,还是使用get('href')](https://liaojinhua.com/zb_users/upload/2020/12/202012071607315015163690.jpg)
获取网页所有a标签中的超链接,使用['href']好,还是使用get('href')
前几天不是用python写了一个一建抓取网站所有链接的小脚步吗,我在里面提了下脚步有点问题,但是不会影响大局观,所以就没有提出来。然而多次运行该脚步后发现了一个对大局观有很大影响的BUG,lia['href']遇到a标签中没有href时,就会像个哈比一样不知道怎么办,这是我在抓取自己博客的时候发现的一个问题,所以脚步写好了,要看其兼容性是否好,还得多找些案例来运行下才行。好了,遇到问题就要解决问题。获取a标签中的href我在之前就写过相关脚步,但是具体怎么写的,因为年纪大了忘记了 ...
-

用pyhon写的一个一键抓取网站所有页面,并排除非本网链接的脚本
最近一直在思考如何能做一个想百度一样的爬虫,能够自行的爬取网站里所有页面,并且排除掉非该网站下的链接。于是,就写了以下的这么个程序。由于本人对于线程还不是了解,刚开始写的初稿并没有加上线程,导致遇到数据多一些的网站,脚本运行时间就很长。这个其实是非常烦恼的,因为调试起来,脚本运行时间太长,会很耽误时间,所以找了个学习Python时在网上认识的一位朋友帮忙加了下线程,才有了以下这段代码:import requests from bs4 import Bea ...
-

python关键词排名查询代码升级版
import requests from fake_useragent import UserAgent from bs4 import BeautifulSoup ua = UserAgent() useragent=ua.firefox headers={'user-agent':useragent} pm=True def fanye(): ...
-

Python 列表(List)使用详解
# 如何创建一个有值的列表# 创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:# str与int混合列表liebiao1=['A','b',1]# 纯int列表liebiao2=[1,2,3]# 纯str列表liebiao3=['a','b','c']# 使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示:print(liebiao1[0],liebiao1[2]) ...
-

python随机启动浏览器,并实现关键词搜索与查找功能代码
import time import random from selenium import webdriver a=random.randint(1,3) if a==1: browser = webdriver.Chrome() elif a==2: browser=webdriver.Fi ...
-

selenium使用google如何使用代理IP
selenium可以模拟浏览器进行点击,但是如果同一IP操作过多,就会出现排斥,从而抓取不到数据。所以,学会使用代理IP是使用selenium的重要一个知识点,下面我就来给大家分享下如何使用代理IP启动google浏览器。下面是代码:from selenium import webdriver from selenium.webdriver import ChromeOptions import time import& ...
-

如何使用python自动搜索,并点击搜索结果
这里是简单版本的自动搜索,并点击,我们只需要输入自己想要搜索的关键词,然后就会自动打开百度搜索,并且将结果一个一个点开,并关闭,这里因为是展示,只设置了搜索第一页,下面是完整代码:import time from selenium import webdriver guanjianci=input('请输入关键词:') browser = webdriver.Firefox() browser.get(' ...