python
-
np.shape的用法详解
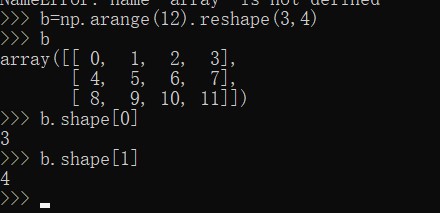
np.shape通俗的来说,就是表示一个数组的形状,比如说创建一个numpy数组b,如下:
b=np.arange(12).reshape(3,4)
使用np.shape(b),结果输出为(3, 4),表示b是一个3行4列的二维数组。
当我们使用b.shape[0],输出结果为:3,表示b有3列
当我们使用b.shape[1],输出结果为4,表示b有4行
... -
IntelliJ IDEA flask如何设置启动后修改文件自动刷新
flask要想在启动后修改文件能够做到自动刷新,需要设置为调试模式,即FLASK_DEBUG = 1的状态。
但是在代码里设置,开启后依然是FLASK_DEBUG = 0,Debug mode: off 的状态。所以,这样设置是无效的。
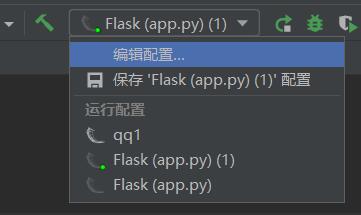
正确的设置方法如下
一、找到编辑配置
... -

已经安装了flask_sqlalchemy,但还是提示ModuleNotFoundError: No module named 'flask_sqlalchemy'
今天在使用flask_sqlalchemy时,发现已经安装了Flask-SQLAlchemy,但是在使用的时候总是提示ModuleNotFoundError: No module named 'flask_sqlalchemy'错误,百度了一圈,没有找到解决的答案,于是我尝试着升级一下这个包。
pip install -U Flask-SQLAlchemy
升级完成之后,再次使用,已经能够正常使用了。
虽然百度没有解决自己的问题,但是发现很多人遇到这样的问题,都是发生在安装的时候,这个的解决方案是,在安装的时候包的名字写错了,正确的安装命令应该是
... -
Python BeautifulSoup如何获取当前元素的父元素
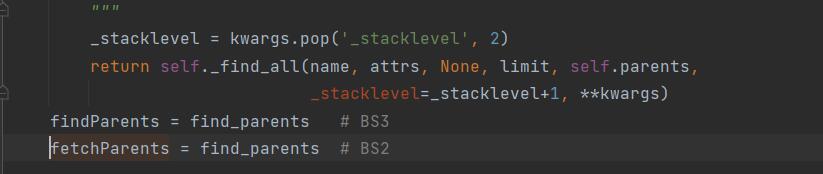
我们在使用BeautifulSoup获取到所有相关元素后,如果需要向上找父类元素,这个时候就需要使用到findParent()或者findParents()。findParent()是找到当前元素的父元素,而findParents()当前元素的所有祖先元素。好比第一是找父亲,后面是找父亲及以上所有亲人。
<div> <div> <p></p> <p></p> <p></p> <p></p> </div> </div>
... -
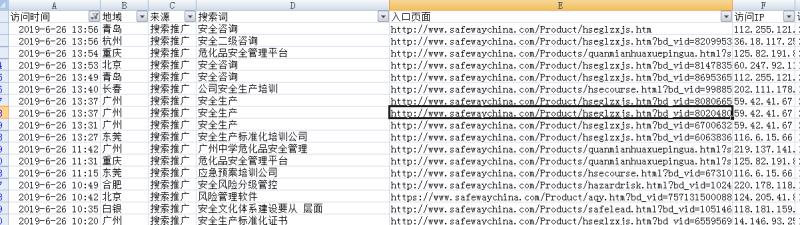
竞价关键词快速分组工具及使用方法介绍,python版
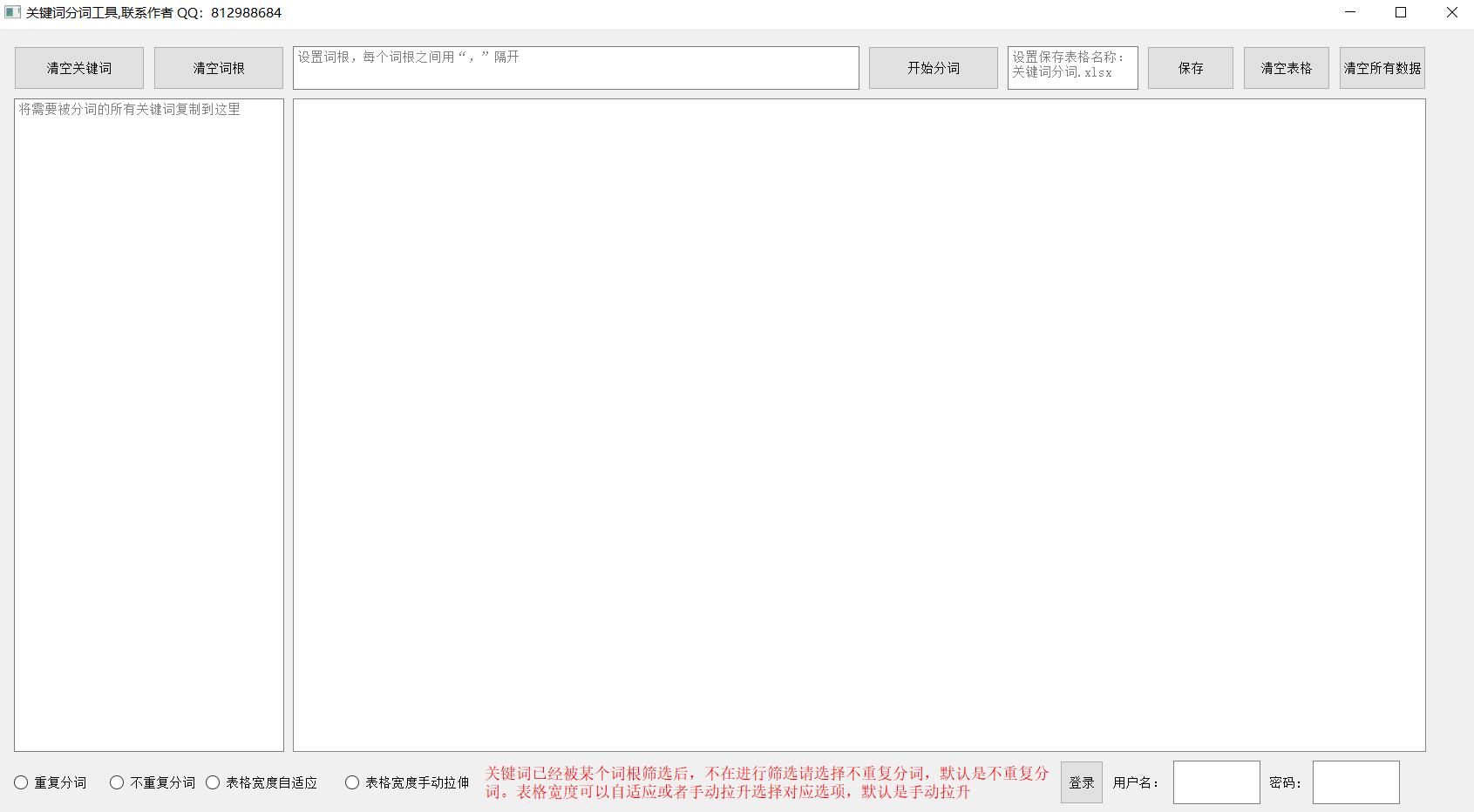
做百度竞价,在搭建账户的时候,我们先需要拓展关键词,这个百度推广后台有关键词规划大师工具可以做到,拓展了几千个关键词后,我们需要使用关键词快速分组工具,来对关键词进行分组处理和筛选。网上搜索能够找到一些免费的相关工具,但是需要正版office才能使用或者是付费的wps,因为需要用到宏处理。所以我自己开发了一个python版的,操作简单,方便,具体操作步骤如下:
首先,我们打开fenci.exe,打开后界面如下图,然后在右下角输入用户名与密码进行登录,没有登录是不可以操作的。:
... -
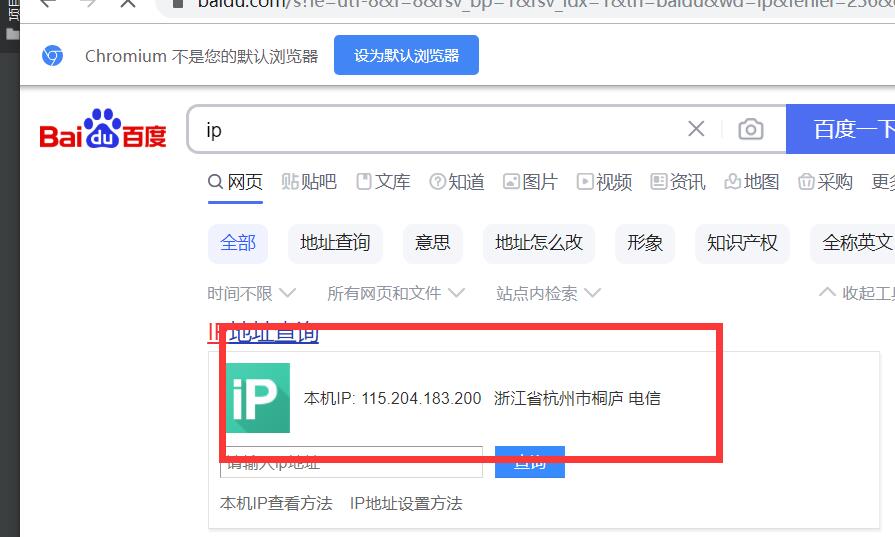
pyppeteer如何设置代理IP
pyppeteer写爬虫程序的时候,很多时候都需要使用到代理IP,那么代理IP在pypeteer中该怎么用呢,下面小编就来给大家分享一下。
具体使用是写在args参数中,代码如下:
import asyncio from pyppeteer import launch,launcher # launcher.DEFAULT_ARGS.remove("--enable-automation") class baidu_Click(): def __init__(self): super(baidu_Click, self).__init__() async def set_browser(self): self.browser=await launch(headless=False,ignoreDefaultArgs=['--enable-automation'],args=['--proxy-server=http://115.204.183.200:4257']) pages=await self.browser.pages() self.page=pages[0] await self.page.goto('https://www.baidu.com') def qidong(self): asyncio.get_event_loop().run_until_complete(self.set_browser()) if __name__ == '__main__': baidu=baidu_Click() baidu.qidong()... -
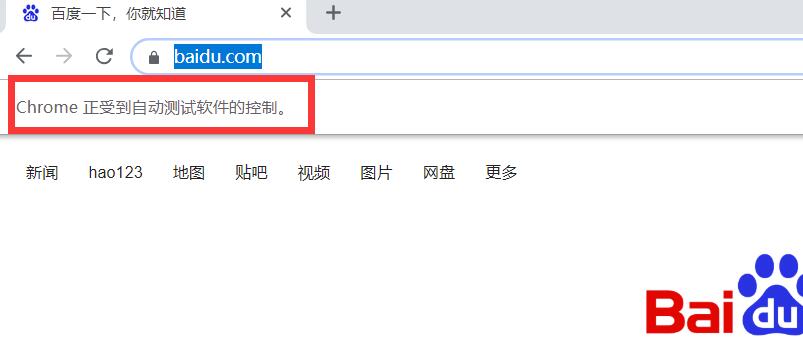
pyppeteer去除Chrome正受到自动测试软件的控制的两种方法
我们再使用pyppeteer启动浏览器的时候,如果没有添加一些操作,浏览器就会显示Chrome正受到自动测试软件,如以下代码:
import asyncio from pyppeteer import launch class baidu_Click(): def __init__(self): super(baidu_Click, self).__init__() async def set_browser(self): self.browser=await launch(headless=False) pages=await self.browser.pages() self.page=pages[0] await self.page.goto('https://www.baidu.com') await asyncio.sleep(10) await self.browser.close() def qidong(self): asyncio.get_event_loop().run_until_complete(self.set_browser()) if __name__ == '__main__': baidu=baidu_Click() baidu.qidong()... -
安装pyqt5-tools失败,error: metadata-generation-failed
C:\Program Files\Python310\Scripts>pip install pyqt5-tools Defaulting to user installation because normal site-packages is not writeable Collecting pyqt5-tools Using cached pyqt5_tools-5.15.4.3.2-py3-none-any.whl (29 kB) Collecting python-dotenv Using cached python_dotenv-1.0.0-py3-none-any.whl (19 kB) Collecting click Using cached click-8.1.3-py3-none-any.whl (96 kB) Collecting pyqt5-tools Downloading pyqt5_tools-5.15.4.3.1-py3-none-any.whl (28 kB) Downloading pyqt5_tools-5.15.4.3.0.3-py3-none-any.whl (28 kB) Downloading pyqt5_tools-5.15.3.3.2-py3-none-any.whl (29 kB) Downloading pyqt5_tools-5.15.3.3.1-py3-none-any.whl (28 kB) Collecting pyqt5==5.15.3 Downloading PyQt5-5.15.3.tar.gz (3.3 MB) ---------------------------------------- 3.3/3.3 MB 9.9 MB/s eta 0:00:00 Installing build dependencies ... done Getting requirements to build wheel ... done Preparing metadata (pyproject.toml) ... error error: subprocess-exited-with-error × Preparing metadata (pyproject.toml) did not run successfully. │ exit code: 1 ╰─> [29 lines of output] Traceback (most recent call last): File "C:\Program Files\Python310\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 144, in prepare_metadata_for_build_wheel hook = backend.prepare_metadata_for_build_wheel AttributeError: module 'sipbuild.api' has no attribute 'prepare_metadata_for_build_wheel' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "C:\Program Files\Python310\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 351, in <module> main() File "C:\Program Files\Python310\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 333, in main json_out['return_val'] = hook(**hook_input['kwargs']) File "C:\Program Files\Python310\lib\site-packages\pip\_vendor\pep517\in_process\_in_process.py", line 148, in prepare_metadata_for_build_wheel whl_basename = backend.build_wheel(metadata_directory, config_settings) File "C:\Users\93186\AppData\Local\Temp\pip-build-env-ab0ybvhq\overlay\Lib\site-packages\sipbuild\api.py", line 46, in build_wheel project = AbstractProject.bootstrap('wheel', File "C:\Users\93186\AppData\Local\Temp\pip-build-env-ab0ybvhq\overlay\Lib\site-packages\sipbuild\abstract_project.py", line 87, in bootstrap project.setup(pyproject, tool, tool_description) File "C:\Users\93186\AppData\Local\Temp\pip-build-env-ab0ybvhq\overlay\Lib\site-packages\sipbuild\project.py", line 585, in setup self.apply_user_defaults(tool) File "C:\Users\93186\AppData\Local\Temp\pip-install-tzd9ej1t\pyqt5_8f912dc4afe440dd801d966213ed42dd\project.py", line 63, in apply_user_defaults super().apply_user_defaults(tool) File "C:\Users\93186\AppData\Local\Temp\pip-build-env-ab0ybvhq\overlay\Lib\site-packages\pyqtbuild\project.py", line 70, in apply_user_defaults super().apply_user_defaults(tool) File "C:\Users\93186\AppData\Local\Temp\pip-build-env-ab0ybvhq\overlay\Lib\site-packages\sipbuild\project.py", line 236, in apply_user_defaults self.builder.apply_user_defaults(tool) File "C:\Users\93186\AppData\Local\Temp\pip-build-env-ab0ybvhq\overlay\Lib\site-packages\pyqtbuild\builder.py", line 69, in apply_user_defaults raise PyProjectOptionException('qmake', sipbuild.pyproject.PyProjectOptionException [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. error: metadata-generation-failed × Encountered error while generating package metadata. ╰─> See above for output. note: This is an issue with the package mentioned above, not pip. hint: See above for details.... -
Pandas如何读取及保存xlsx文件
Pandas读取xlsx文件需要用到的方法是read_excel()
io参数
io参数可以接受的有:str,Excel文件,xlrd.Book,路径对象或类似文件的对象,其中最常用的是str,一般是文件路径+文件名,需要注意的是文件名字不要漏掉后缀,即文件扩展名,表明文件类型的那个!有时候需要对路径中的”\”进行转义,io参数没有默认值,必须传入。
... -

错误提示:Matplotlib 3.6 and will be removed two minor releases later如何解决
源代码:
from tensorflow import keras fashion_mnist=keras.datasets.fashion_mnist (train_images,train_labels),(test_images,test_labels)=fashion_mnist.load_data() from matplotlib import pyplot as plt # plt.plot(train_images[0]) # plt.grid(True) plt.imshow(train_images[0]) plt.show()
...